한국의 개발자들을 위한 Google for Developers 국문 블로그입니다.
BiT 오픈 소스 공개: 컴퓨터 비전을 위한 대규모 사전 훈련
2020년 6월 3일 수요일
작성자 : Lucas Beyer, Alexander Kolesnikov (
Google Research 리서치 엔지니어)
원문은
여기
서
확인할 수 있으며
블로그 번역 리뷰는 박해선(ML GDE)님이 참여해 주셨습니다
.
컴퓨터 비전 연구자들은 최신 심층 신경망에서는 늘 더 많은 레이블된 데이터가 필요하다고 종종 불평합니다. 현재 최고 수준의 CNN은
OpenImages
나
Places
와 같은 데이터셋에서 훈련해야 합니다. 이런 데이터셋은 1백만 개 이상의 레이블된 이미지로 구성되어 있습니다. 하지만 많은 애플리케이션에서
이런 양의 레이블된 데이터
를 모으는 것은 평범한 기술자들에게 엄두도 낼 수 없는 일입니다.
컴퓨터 비전 작업에서 레이블 데이터 부족을 보완하기 위해 널리 사용하는 방법은 범용 데이터(예를 들면
ImageNet
)에서 사전 훈련된 모델을 사용하는 것입니다. 범용 데이터에서 훈련한 비주얼 특성을 주어진 문제를 위해 재사용할 수 있습니다. 사전 훈련 방식이 실전에서 꽤 잘 동작하지만 새로운 개념을 파악하고 서로 다른 맥락에서 이해하는 능력은 여전히 부족합니다. 하지만 비슷한 관점에서
BERT
와
T5
가 언어 영역에서 보여준 발전을 보면 대규모 사전 훈련이 컴퓨터 비전 모델의 성능을 높일 수 있다고 생각합니다.
우리는 “
Big Transfer (BiT): General Visual Representation Learning
” 논문에서 사실상 표준인 데이터셋(
ILSVRC-2012
)을 넘어서 대규모 이미지 데이터셋을 사용한 효과적인 범용 특성의 사전 훈련 방법을 제시했습니다. 특히 사전 훈련 데이터 양이 증가할수록 적절한 정규화 층 선택과 네트워크 용량 확장이 중요하다는 점을 강조했습니다. 퓨-샷few-shot 인식 테스트와 최근에 소개된 “현실적인"
ObjectNet
벤치마크를 포함해 다양한 새로운 비전 작업에 적용하여 이전에 없던 성능을 달성했습니다. 기쁜 소식이 있습니다. 공개 데이터셋에서 사전 훈련한
최고의 BiT 모델
을
TF2, Jax, PyTorch 코드
와 함께 공개합니다. 이제 누구라도 클래스마다 약간의 레이블된 이미지를 가지고 주어진 작업에서 최고 수준의 성능에 도달할 수 있습니다.
사전 훈련
데이터 크기에 따른 영향을 조사하기 위해 3개의 데이터셋과 많이 사용하는 사전 훈련 설정(활성화와 가중치 정규화, 모델의 깊이와 너비, 훈련 스케줄 등)을 사용했습니다. 이 데이터셋은 ILSVRC-2012 (1,000개의 클래스로 구성된 1.28백만 개의 이미지),
ImageNet-21k
(~2만 1천개의 클래스로 구성된 1천 4백만 개의 이미지),
JFT
(~1만 8천개의 클래스로 구성된 300백만 개의 이미지)입니다. 이 3개의 데이터셋을 사용해 이전에 잘 다루지 않았던 대규모 데이터 설정에 초점을 맞추었습니다.
먼저 데이터셋 크기와 모델 용량 사이의 상호 작용을 조사했습니다. 이를 위해 간단하고 재현이 용이하지만 성능이 좋은 기본
ResNet
모델을 훈련했습니다. 기본 50층 깊이의 “R50x1”에서 4배 넓고 152층 깊이를 가진 “R152x4” 모델까지 위에서 언급한 데이터셋으로 훈련했습니다. 늘어난 데이터의 장점을 얻으려면 모델 용량을 늘려야 한다는 점이 관측되었습니다. 아래 그림의 왼쪽 편에 있는 빨간 화살표가 이를 나타냅니다.
왼쪽: 사전 훈련을 위해 대규모 데이터셋을 효과적으로 사용하려면 모델 용량을 늘려야 합니다. 빨간 화살표가 이에 대한 예시입니다. 작은 모델(작은 원)은 대규모 ImageNet-21k 데이터셋에서 사전 훈련할 때 성능이 낮아졌지만 큰 용량의 모델(큰 원)은 향상되었습니다. 오른쪽: 대규모 데이터셋에서 사전 훈련이 반드시 성능을 향상하는 것은 아닙니다. 예를 들어 ILSVRC-2012에서 상대적으로 더 큰 ImageNet-21k 데이터셋으로 바꾸었을 때입니다. 하지만 컴퓨팅 리소스를 늘리고 훈련을 더 오래하면 성능이 향상됩니다.
그다음 더 중요한 점은 훈련 기간이 아주 중요하다는 것입니다. 컴퓨팅 리소스와 훈련 시간을 늘리지 않고 대규모 데이터셋에 사전 훈련하면 성능이 더 나빠질 가능성이 있습니다. 하지만 새로운 데이터셋에 학습 스케줄을 맞추면 크게 향상될 수 있습니다.
조사하는 단계에서 성능을 향상하는데 중요한 다른 수정 사항을 발견했습니다.
배치 정규화
(BN, 활성화를 정규화하여 훈련을 안정시키기 위해 널리 사용하는 층입니다)을
그룹 정규화
(GN)로 바꾸면 대규모 사전 훈련에 도움이 됩니다. 첫째, BN의 상태(활성화의 평균과 분산)는 사전 훈련과 전이 학습 사이에 조정이 필요합니다. 하지만 GN은 상태가 없어서 이런 문제를 피할 수 있습니다. 둘째, BN은 배치 수준의 통곗값을 사용하기 때문에 대규모 모델에서 어쩔 수 없이 사용하는 장치당 작은 배치 사이즈에서 불안정합니다. GN은 배치 수준의 통곗값을 계산하지 않기 때문에 이 이슈를 피해갑니다. 안정된 성능을 위한
가중치 표준화
기법을 포함하여 조금 더 기술적인 내용은 논문을 참고하세요.
사전 훈련 전략 요약: 표준 ResNet에서 깊이와 너비를 늘리고 BatchNorm(BN)을 GroupNorm과 가중치 표준화(GNWS)로 바꿉니다. 그리고 매우 크고 범용적인 데이터셋에 오랫동안 훈련합니다.
전이 학습
언어 모델에서
BERT
가 세운 방법을 따라 사전 훈련된 BiT 모델을 다양한 작업을 위한 데이터에서 세부 튜닝했습니다. 이런 작업들은 레이블된 데이터가 매우 적습니다. 사전 훈련된 모델은 이미 세상을 바라보는 방법을 이해하고 있기 때문에 간단한 이런 방법이 아주 잘 동작합니다.
세부 튜닝할 하이퍼파라미터는 학습률, 가중치 감쇠 등을 포함해 많습니다. 이런 하이퍼파라미터를 선택하는 경험적인 방법으로
“BiT-HyperRule”
을 제안합니다. 이 방법은 이미지 해상도와 레이블된 샘플의 수와 같이 데이터셋의 고수준 특성을 기반으로 합니다. 자연 이미지에서 의학 이미지까지 20개 이상의 다양한 작업에 BiT-HyperRule을 성공적으로 적용했습니다.
BiT 모델을 사전 훈련하고나면 레이블된 샘플이 적은 어떤 작업에서도 세부 튜닝할 수 있습니다.
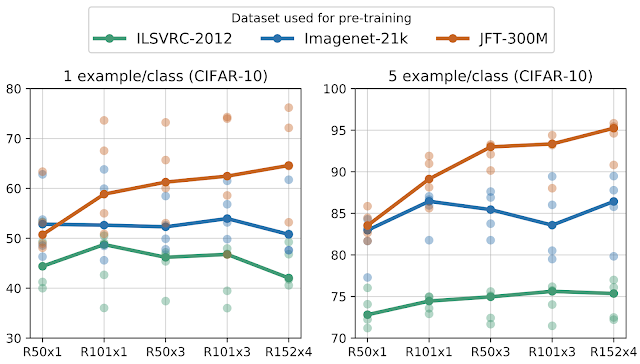
BiT 모델을 샘플이 매우 적은 작업에 전이 학습할 때 사전 훈련에 사용한 범용 데이터의 양과 모델의 용량을 같이 늘려야 새로운 데이터에 적용하는 결과 모델의 성능이 크게 향상한다는 것을 관찰했습니다. 1-샷과 5-샷 CIFAR(아래 그림 참조)의 경우 ILSVRC에서 사전 훈련할 때 모델 용량을 증가하면 성능 향상이 제한적입니다(녹색 곡선). 하지만 JFT에서 대규모 사전 훈련하면 모델 용량을 늘릴 때마다 성능이 크게 향상됩니다(갈새 곡선). BiT-L 모델이 64%의 1-샷과 95%의 5-샷을 달성했습니다.
이 곡선은 5번 독립적으로 실행(밝은 원)하여 얻은 평균 정확도입니다. 클래스 당 1개 또는 5개 이미지(총 10개 또는 50개 이미지)를 가진 CIFAR-10에 전이 학습했을 때입니다. 대규모 데이터셋에 사전 훈련한 대용량 모델이 적은 데이터를 더 잘 활용한다는 증거입니다.
이 결과를 더 일반적으로 검증하기 위해
VTAB-1k
에서도 BiT를 평가했습니다. VTAB-1K는 19개의 다른 작업으로 이루어져 있고 각 작업마다 레이블된 샘플이 1,000개 뿐입니다. BiT-L 모델을 이 작업에 모두 전이 학습하여 전체적으로 76.3%의 점수를 달성했습니다. 이는
최고 수준의 이전 성능
보다 5.8% 향상된 것입니다.
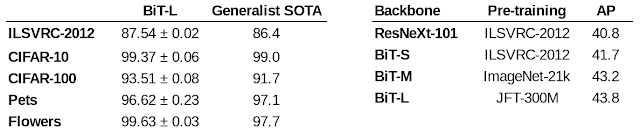
대규모 사전 훈련과 단순한 전이 학습 전략이 중간 규모의 데이터가 있는 경우에도 사용할 수 있습니다. BiT-L을 옥스포드
Pets
,
Flowers
,
CIFAR
등과 같은 몇 가지 표준 컴퓨터 비전 벤치마크에서 평가하여 확인했습니다. 이 모든 테스트에서 BiT-L은 최고 수준의 성능과 동일하거나 더 우수한 결과를 냈습니다. 마지막으로
MSCOCO-2017
감지 작업에서 BiT를
RetinaNet
의 백본으로 사용하여 구조적인 출력을 내는 작업에서도 대규모 사전 훈련을 사용하는 것이 큰 도움이 된다는 것을 보였습니다.
왼쪽: 여러 가지 표준 컴퓨터 비전 벤치마크에서 최고 수준의 이전 모델과 비교한 BiT-L의 정확도. 오른쪽: MSCOCO-2017에서 RetinaNet의 백본으로 BiT를 사용했을 때 평균 정밀도(AP) 결과.
여기에서 다룬 여러 종류의 후속 작업에서 하이퍼파라미터 튜닝을 수행하지 않고
BiT-HyperRule
에 의존했다는 것이 중요합니다. 논문에 있는 것처럼 충분한 양의 검증 데이터에서 하이퍼파라미터 튜닝을 하면 더 나은 결과를 얻을 수 있습니다.
ObjectNet에서 평가
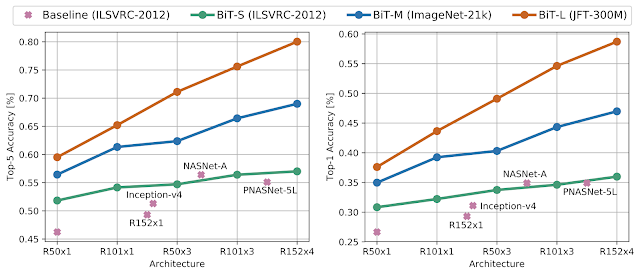
조금 더 도전적인 상황에서 BiT의 안정성을 평가하기 위해 ILSVRC-2012에서 세부 튜닝된 BiT 모델을 최근에 소개된
ObjectNet
데이터셋에서 평가했습니다. 이 데이터셋은 실제 상황에 매우 가깝습니다. 물체들이 일반적이지 않은 상황, 관점, 각도 등을 가지고 나타납니다. 놀랍게도 데이터와 모델의 규모로 인한 잇점이 BiT-L 모델에서 더욱 두드러졌습니다. 이전에 없던 80%의 톱-5 정확도를 달성했습니다. 이는
최고 수준의 이전 모델
보다 25%나 향상된 것입니다.
ObjectNet 평가 데이터셋에서 BiT 모델의 결과. 왼쪽: 톱-5 정확도, 오른쪽: 톱-1 정확도.
결론
많은 양의 범용 데이터에서 사전 훈련한 후 간단한 전이 학습 전략은 클래스당 하나의 이미지가 있는 매우 적은 데이터를 가진 작업은 물론 많은 양의 데이터셋에서도 놀라운 성과를 냅니다. ImageNet-21k에서 사전 훈련한 R152x4 사전 훈련 BiT-M 모델을 Jax, TensorFlow2, PyTorch에서 전이 학습하는 코랩 노트북과 함께
공개
합니다. 코드 공개와 함께 BiT 모델을 따라해 볼 수 있는
TensorFlow2 튜토리얼
도 제공합니다. 널리 사용되는 ImageNet 사전 훈련 모델외에 기술자들과 연구자들에게 좋은 대안이 되기를 바랍니다.
감사의 말
BiT 논문의 공동 저자이고 모델 개발의 모든 부분에 참여해 준 Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby와 취리히의 Brain 팀에게 감사합니다. 입력 파이프라인 디버깅을 도와준 Andrei Giurgiu에게도 감사합니다. 이 블로그에 사용할 애니메이션을 만들어 준 Tom Small에게 감사합니다. 마지막으로 관심있는 독자들에게 이와 유사한 접근 방법인 Google Research 동료들의
Noisy Student
, Facebook Research의
Exploring the Limits of Weakly Supervised Pretraining
를 추천합니다.
Contents
ML/Tensorflow
Android
Flutter
Web/Chrome
Cloud
Google Play
Community
Game
Firebase
검색
Tag
인디게임페스티벌
정책 세미나
창구프로그램
AdMob
AI
Android
Android 12
Android 12L
Android 13
Android 14
Android Assistant
Android Auto
Android Games
Android Jetpack
Android Machine Learning
Android Privacy
Android Studio
Android TV
Android Wear
App Bundle
bootcamp
Business
Chrome
Cloud
Community
compose
Firebase
Flutter
Foldables
Game
gdg
GDSC
google
Google Developer Student Clubs
Google I/O
Google Play
Google Play Games
Interview
Jetpack
Jetpack Compose
kotlin
Large Screens
Library
ma
Material Design
Material You
ML/Tensorflow
mobile games
Now in Android
PC
Play Console
Policy
priva
wa
wear
Wearables
Web
Web/Chrome
Weeklyupdates
WorkManager
Archive
2026
7월
6월
5월
4월
3월
2월
1월
2025
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2024
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2023
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2022
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2021
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2020
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2019
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2018
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2017
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2016
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2015
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2014
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2013
12월
11월
10월
9월
8월
7월
6월
5월
4월
3월
2월
1월
2012
12월
11월
10월
9월
8월
7월
6월
5월
3월
2월
1월
2011
12월
11월
Feed